-
[String Matching] KMP Algorithm ( 2 )Algorithm 2022. 11. 14. 12:22
KMP 알고리즘을 확장 구현하고, 각 패턴에 따라서 탐색하고 패턴이 발생한 모든 위치를 찾을 수 있는지 확인.
KMP 알고리즘의 동작에 대한 분석과 직접 구현한 코드에 대한 설명, 패턴에 따른 탐색의 분석이 포함됨.2022.11.14 - [Algorithm] - [String Matching] KMP Algorithm ( 1 )
[String Matching] KMP Algorithm ( 1 )
KMP 알고리즘을 확장 구현하고, 각 패턴에 따라서 탐색하고 패턴이 발생한 모든 위치를 찾을 수 있는지 확인. KMP 알고리즘의 동작에 대한 분석과 직접 구현한 코드에 대한 설명, 패턴에 따른 탐색
kkastory.tistory.com
Implementation
readFile Function
주어진 파일을 읽어서 string 변수에 저장하기위한 함수이다. file이 오픈되었다면, 텍스트의 끝으로 이동하여 그때의 인덱스를 사이즈로 저장하고, string변수의 사이즈를 다시 조절하여 텍스트 파일의 처음부터 저장한다. 그 후에 string 변수를 리턴한다.
string readFile(ifstream& inputFile, string t){ if(inputFile.is_open()) //file이 오픈되었다면, { inputFile.seekg(0, ios::end); //텍스트파일의 끝으로 간다. auto size = inputFile.tellg(); //텍스트 파일의 현재위치값을 사이즈로 저장한다. t.resize(size); //텍스트를 저장할 t의 사이즈를 바꿔준다. inputFile.seekg(0, ios::beg); //텍스트파일의 처음으로 간다. inputFile.read(&t[0], size); //input file의 0부터 t에 덮어씌운다. } return t; //string 을 리턴한다. }KMPSearcher Class
KMP알고리즘과 관련된 initNext()함수와 KMP()함수를 KMPSearcher 이라는 클래스로 묶어주었다. initNext()함수부터 살펴보면, 인자로 패턴을 받고, 그 패턴의 불일치 시의 위치를 저장하는 next 배열을 만든다. 이는 개선된 유한 상태 장치를 만들기 위해서 패턴의 문자가 같을 때, 같은 문자 중 가장 첫번째 문자가 불일치 시에 이동하는 위치로 모두 이동하게끔 삼항연산자를 사용하여 값을 저장해주었다. 그 후에 while 문을 이용하여 패턴들이 이동하는 위치를 재검사 하여 저장한다.
int cnt = 0; //패턴을 확인하였을때 위치 저장을 위한 배열의 index 값 class KMPSearcher{ //KMP 에 필요한 함수 모아놓은 클래스 public: int* initNext(string p){ //Next 배열을 만드는 함수. int M = (int)p.size(); int* next = new int[M]; //next 배열을 저장할 함수 next[0] = -1; //[0]자리에 -1을 저장. for(int i=0, j=-1; i<M; i++, j++){ //개선된 유한 상태 장치를 이용하여 next 배열을 만든다. // => 탐색 시작 글자가 같으면 시작해야하는 위치또한 같기 때문에 아예 첫글자로 돌아가게끔 next 배열을 만든다. next[i] = (p[i] == p[j]) ? next[j] : j; //i, j 위치에 있는 패턴 값이 같으면 next[j], 아니면 j 저장. while(j>=0 && p[i] != p[j]) j = next[j]; //재검사 => i, j 위치에 있는 패턴 값이 같지 않으면 next[j]값으로 옮긴다. } //next 배열 확인용 cout<<"Next Array [ "; for(int i=0; i<M; i++) cout<<next[i]<<" "; cout<<"]"<<endl; return next; //next 배열을 리턴한다. }KMP()함수는 인자로 Text와 Pattern을 받는다. KMP 함수가 실행되면, 먼저 initNext()함수를 이용하여 pattern의 next 배열을 구해온다. 그 후에 화일문을 돌면서 패턴이 매칭되었을 때의 값을 새로운 배열 pos에 저장하게끔 한다. 화일문에 들어가면 텍스트와 패턴의 원소끼리 비교를 들어간다. 이때 패턴이 옮겨갈 위치를 next 배열을 이용해서 정해준다. 만약 패턴의 인덱스 값이 패턴의 크기 만큼 됐다면, 즉 텍스트에서 패턴을 찾았다면, pos배열에 패턴을 찾은 head 위치를 저장한다. 이때 cnt 라는 전역 int 변수를 패턴을 찾았을 때 +1 씩 증가시키면서 그 다음 패턴을 찾았을때는 그 다음 위치의 pos배열에 저장되게끔 하였다. 패턴을 찾았다면, j = 0, 즉 패턴의 탐색위치를 처음으로 초기화 시켜준다.
그리고 텍스트에서 패턴을 매칭할 다음 위치를 찾는데 두가지 방법을 구상해 봤다.
첫 번째로, 패턴이 매칭 된 후에 그 다음 텍스트에서 탐색을 시작할 위치를 패턴을 찾은 위치 바로 다음으로 초기화 시키는 방법이다. 따라서 i 값은 패턴을 발견한 위치 다음으로 초기화 시켜주었다. 하지만 이는 similar과 같이 패턴 안에서 첫번째 문자와 동일한 문자가 없다면, 그 패턴 길이만큼의 텍스트에서는 절대 패턴이 겹쳐질 수 없다.
따라서 두번째 방법으로 firstIsAlone 이라는 함수를 이용하여 해당 패턴 안에서 첫번째 문자와 같은 문자를 가지는 것이 있는지 체크하는 bool 함수를 만들었다. 만약 있다면 false를 리턴하고, 첫번째 문자와 동일한 문자가 없다면 true를 리턴한다. 이는 Next 배열을 만들 때 개선된 유한 상태 장치로 사용되게 끔 만들었기 때문이다. 즉 첫번째 문자와 같은 문자라면 비교를 첫 문자와 같은 위치부터 하게끔 하기 때문에 만약 첫 문자와 같은 문자가 패턴 안에 있다면, 그 동일한 문자가 불일치 시에 돌아가는 위치의 첫 문자의 돌아가는 위치, 즉 -1일 것이다. 이를 이용하여 -1의 개수를 카운팅 하여 만약 0보다 크다면 첫 문자와 같은 문자가 있다고 판단하여 false를 리턴하게 하는 것이다. KMP함수에 들어온 패턴은 while 문이 끝날때 까지 동일하므로, KMP 함수가 처음 시작할 때 firstIsAlone 의 bool 값을 저장해 놓는다.
int* KMP(string t, string p){ int N = (int)t.size(), M = (int)p.size(); int i = 0, j = 0; int* next = initNext(p); //next 배열을 불러온다. bool isAlone = firstIsAlone(next, M); //패턴안에서 패턴의 첫 문자와 같은 문자가 있는지 next 배열을 이용해 검사. int* pos = new int[N]; //패턴을 찾았을때의 위치값을 저장하는 배열. 임의로 텍스트 크기로 선언하였다. //실습에서의 kmp 코드와 달라진 부분 while(i<N){ //i가 N값과 같아질 때 까지 화일문 마지막에 +1씩 증가시킨다. while(j>=0 && t[i] != p[j]) j = next[j]; //검사하고 패턴과 매칭되지 않으면 next[j]로 옮긴다. if(j == M-1){ //패턴의 인덱스값이 패턴 크기 -1 이 됐을때, 즉 패턴을 찾았을때 pos[cnt] = i - M + 1; //패턴을 찾은 위치를 배열에 저장한다 cnt++; //인덱스 값을 올려준다. j = 0; //패턴의 위치를 초기화 //패턴을 찾은 위치 다음으로 인덱스를 변경한다. //** 방법 1 //i = i - M + 2; //패턴을 찾았을때 비교할 텍스트의 위치를 패턴을 찾은 위치 바로 다음으로 초기화 시킨다. //** 방법 2 if(!isAlone) i = nextPosition(t, p, i, M); //패턴안에 첫 문자와 같은 문자가 있으면 else i++; } else{//패턴을 찾지 못하면 j++; i++;// j와 i의 위치는 다음인덱스로 넘긴다. } } return pos; //패턴을 찾았을 때의 위치를 저장한 배열을 리턴한다. }위의 값을 이용하여 만약 패턴안에 첫번째 문자와 동일한 문자가 있다면 거기서부터 탐색을 시작하는 함수인 nextPosition()함수를 만들었다.
인자로는 텍스트와 패턴, 현재 텍스트의 인덱스와 패턴의 크기가 들어간다.
bool firstIsAlone(int* next, int M){//패턴안에서 패턴의 첫 문자와 같은 문자가 있는지 검사하는 함수. int same = 0; if(M<=1) return true; else{ for(int k=1; k<M; k++) if(next[k] == -1) same++; //next 배열에서 -1값을 찾으면, 즉 첫 글자와 동일한 글자가 있다면 } if(same > 0) return false; //패턴안에 첫 문자와 같은 문자가 하나라도 있다면 false 리턴. else return true; //패턴안에 첫 문자와 같은 문자가 하나도 없다면 true 리턴. }패턴을 찾은 위치의 다음부터 패턴크기만큼 텍스트( 에서 패턴을 검사하였으니 패턴), 즉 패턴을 품은 텍스트부분만 재 검사하여 패턴의 첫 문자와 동일한 문자가 처음 나타나는 위치를 리턴한다. 처음 나타나는 위치를 리턴해야 하므로, 동일한 문자가 나타나는 위치를 찾았다면 break문으로 for 문을 빠져나온다.
첫번째 방법과 비교해보면 패턴이 길거나, 혹은 패턴 안에 겹치는 글자가 없는 경우에는 두번째 경우가 빠를 것이다. 하지만 aa와 같은 단순한 패턴을 찾을 때는 text 의 인덱스를 바로 다음으로 옮겨주는 첫번째 방법이 더욱 빠를 것이다. 위의 두가지 방법을 이용하여 패턴이 매칭이 되었을 때의 text index 값을 잘 설정해 주고, whlie문을 계속 실행한다. 패턴이 매칭 되지 않았을 때는 j와 i인덱스를 각각+1, 다음으로 옮겨주면 된다. while 문이 끝났다면, 패턴이 매칭 되었을 때의 위치 값이 저장된 pos배열의 주소 값을 리턴해준다.
int nextPosition(string t, string p, int i, int M){ //다음 text의 위치를 효율적으로 찾는 함수. for(int k=i-M+2; k<=i; k++) //패턴을 찾은 위치의 다음부터 패턴 크기 만큼까지 텍스트 재 검사 if(t[k] == p[0]){ i = k; //텍스트에서 찾은 패턴에서 패턴의 첫번째 글자와 매칭되었다면 매칭 된 위치값 리턴. break; //찾은위치에서 처음에서 멈춰야하므로 x } return i; } };main Function
메인 함수에서는 변수들을 선언하고, 입력하는 pattern을 getline 함수로 읽어와 p string 변수에 저장한다. 그 다음 과제에 주어진 텍스트 파일을 readFile 함수를 이용하여 읽은 후, 알고리즘 실행 시간을 측정하기 위해 타이머로 측정을 한다. KMPSearcehr 클래스의 KMP 함수를 실행한후의 return 값인 패턴이 매칭되었을 때의 위치값을 저장한 pos 배열의 주소값을 matched 포인터 변수에 저장한다. 타이머를 종료한 후 패턴이 발견된 횟수와 패턴을 발견한 위치, 그리고 모두 발견까지에 걸린 시간을 출력한다.
int main(){ KMPSearcher kmp; string t,p, test; //string text와 pattern ifstream inputFile("RFC2616_modified.txt"); steady_clock::time_point start, end;//timer 시작, 끝 nanoseconds result; //측정시간을 nano second 단위로 출력. cout<<"Pattern : "; getline(cin, p); //입력한 pattern을 불러온다. t = readFile(inputFile, t); //readFile이라는 함수로 텍스트 파일을 읽어온 후 t에 저장한다. start = steady_clock::now(); int* matched = kmp.KMP(t,p); //패턴을 찾았을때의 위치가 저장된 배열을 matched에 저장. end = steady_clock::now(); result = end - start; cout<<"발견 횟수 : "<<cnt<<"\n발견 위치 : "; for(int i = 0; i<cnt; i++) cout<<matched[i]<<" "; //패턴을 찾은 위치를 출력. cout<<"\n발견에 걸린 시간 : "<<result.count()<<"ns"<<endl; //알고리즘 실행시간 return 0; }Result
test.txt 에 대한 패턴 탐색 테스트


abab 패턴을 탐색하여 총 2번의 탐색이 되었고, 위치는 각각 1번째와 3번째, 인덱스 값으로 0과 2에서 발견되었다.

aa 패턴을 탐색하여 총 4번 매칭되는 것을 확인하였다.
RFC2616.txt에 대한 숫자와 특수기호 탐색
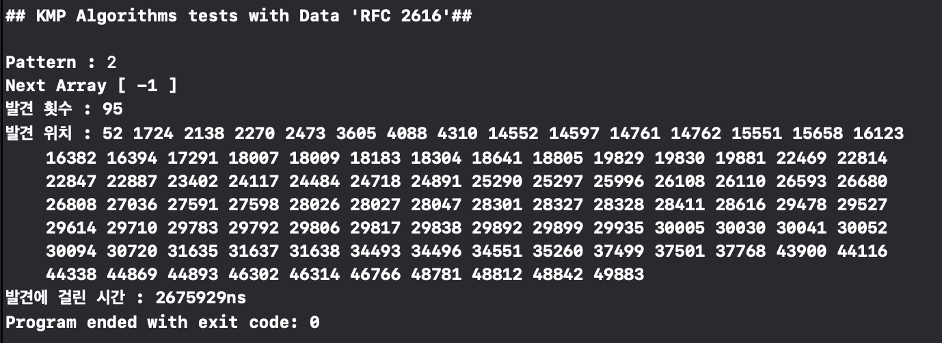
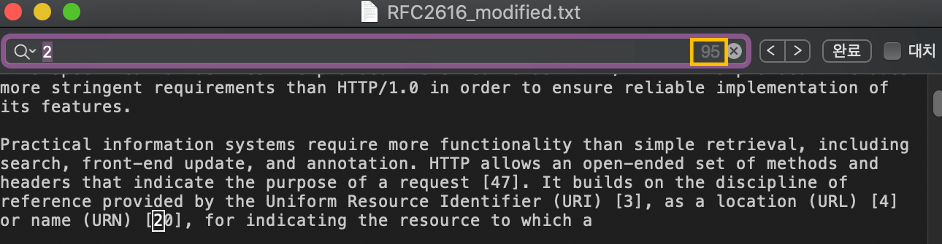
숫자 2를 패턴으로 하여 탐색을 시도하였을 때 총 95개 탐색되는 것을 확인하였다. 이는 텍스트에서 cmd+f 즉 찾기 기능을 사용하여 검색한 결과와 같은 것을 확인할 수 있다.

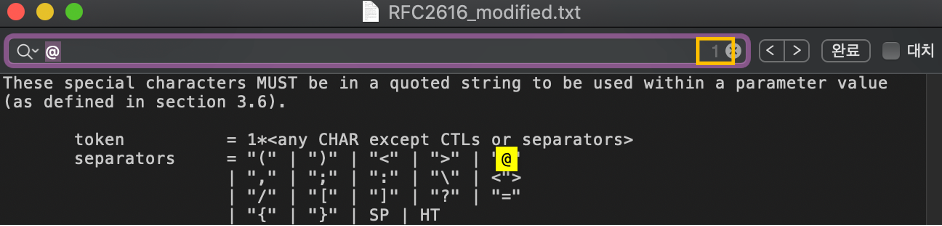
특수기호 @를 확인해 보았다. 알고리즘을 실행한 결과 발견횟수는 1이였고, 이를 텍스트 파일에서 검색해본 결과 마찬가지로 한번만 탐색되는것을 확인하였다.
similar, representation 탐색




다음 text index 를 구하는 방법에 따른 차이
첫 문자와 동일한 문자가 없는 경우 "architectures"


첫 문자와 동일한 문자가 있는 경우 "representation"


Conclusion
위의 결과 들로 알 수 있듯이 패턴을 찾은 후에 바로 그 다음 자리로 옮겨서 탐색을 수행하는 것이 다른 방법을 사용하여 텍스트의 다음 위치를 찾은 후에 패턴 매칭을 수행 하는 것 보다 빠른 것을 알았다. 패턴의 길이가 더 길어진다면 두 번째 방법이 더 빠를 것 같지만, 이번에 탐색을 시도한 패턴들을 다 짧기 때문에 두번째 방법으로 함수 두개를 거쳐서 오는 방법 보다 탐색을 그냥 주욱 하는게 더 빠른 것 같다. 그리고 실행 결과를 확인해 보니 내가 만든 코드는 kmp의 기본 실행시간 O(N+M) 보다 더 걸릴 것 같다. 왜냐하면 패턴이 매칭 되었을 때, 텍스트가 품은 패턴 안에서 한번 더 탐색을 실행하기 때문이다.
따라서 찾으려는 패턴의 길이가 많이 길지 않다면 패턴이 매칭 되었을 때, 매칭 된 위치 바로 다음으로 텍스트의 인덱스를 옮겨서 다시 탐색을 수행하는 것이 더 효율적인 것 같다.
실생활에서 항상 사용하는 검색 기능을 직접 구현해보았다. 구현한 알고리즘 코드를 실행하여 확인했을 때 텍스트 파일에서 검색한 것과 같은 결과가 나왔다. 하지만 직접 생각하여 수정한 KMP 탐색 함수들이, 단순히 옆자리로 옮긴 것보다 성능이 안좋은 것 같아서 조금 더 연구를 해봐야할 것 같다.
'Algorithm' 카테고리의 다른 글
[String Matching] KMP Algorithm ( 1 ) (0) 2022.11.14 [정렬알고리즘] 5개 정렬 알고리즘 비교 (0) 2022.11.14 [정렬알고리즘] Odd Even Merge Sort 홀짝합병정렬 (0) 2022.11.14 [정렬알고리즘] Bitonic Sort 바이토닉 정렬 (0) 2022.11.14 [정렬알고리즘] Shell Sort 쉘 정렬 (1) 2022.11.14