-
[Jetson Nano] Jetson Nano 에서 Object Detection ( DetectNet, SSD-MobileNetv2, Pytorch )Robot, Autonomous Vehicle 2021. 3. 24. 12:51
Hello AI World - python 10줄로 Jetson nano에서 Object detection 하기
Can be run completely onboard your Jetson(Nano/TX1/TX2/Xavier NX/AGX Xavier) , including inferencing with TensorRT and transfer learning with PyTorch.
The inference portion of Hello AI World - which includes coding your own image classification and object detection applications for Python or C++, and live camera demos.
- System Setup
- Setting Jetson with Jetpack
- Running the Docker Container : image recognition, object detection with localization ( bbox) , semantic segmentation 을 위한 TensorRT 가속 딥 러닝 네트워크 라이브러리가 Docker 저장소와 함께 제공. 추론 라이브러리 ( libjetson-inference) 는 Jetson에서 실행되도록 설계. 프로젝트를 컴파일하거나 Pytorch를 직접 설치할 필요가없이 사전 빌드된 Docker 컨테이너 실행할 수 있다.
- or Building the Project from Source : 혹은 직접 프로젝트 소스를 빌드한다.
- Inference
- Using the ImageNet Program on Jetson
- Coding Your Own Image Recognition Program (Python)
- Coding Your Own Image Recognition Program (C++)
- Running the Live Camera Recognition Demo
- Training
- Transfer Learning with PyTorch
- Classification/Recognition (ResNet-18)
- Object Detection (SSD-Mobilenet)
- Collecting your own Detection Datasets
Jetson Inference
use Nvidia TensorRT for efficiently deploying neural networks onto the embedded Jetson Platform, improving performance and power efficiency using graph optimisations, kernel fusion, and FP16/INT8 precision.
NVIDIA TensorRT detectNet
NVIDA에서 제공하는 Deep Learning GPU Training System DIGITS에 포함된 딥러닝 기반 객체 검출 알고리즘으로, 작거나 겹쳐진 객체 검출 성능이 매우 우수하고 처리속도 또한 빠른 것이 장점. 매우 큰 객체가 검출된다는 단점도 있다.
https://developer.nvidia.com/blog/detectnet-deep-neural-network-object-detection-digits/
DetectNet : Deep Neural Network for Object Detection in DIGITS(NVIDIA Deep Learning GPU Training System )
Using DIGITS,
- can perform common deep learning tasks such as managing data, defining networks, training several models in parallel, monitoring training performance in real time, choosing the best model from the results browser
DetectNet은 DIGITS4에서 표준 모델 정의로 제공, Caffe 딥 러닝 프레임워크를 사용해 훈련된다.
- DetectNet 데이터 형식
- => 이 문제해결하기 위해 DetectNet은 3-dimensional lable format을 정의.
- images labeled by class -> Image classification training data samples
- DetectNet의 sample images는 multiple object를 포함하는 큰 이미지이다.
- image내의 객체의 training label은 class뿐만 아니라 corner의 coordinates도 capture해야한다.
- Object의 수는 training image마다 다르기 때문에, 길이와 차원이 다양한 label형식을 naive하게 선택하면 손실함수를 정의하기 어렵다.

- DIGITS가 DetectNet학습을 위해 주석이 달린 학습 이미지를 수집하는데 사용하는 프로세스.
- DIGITS는 감지하려는 가장 작은 물체보다 약간 더 작은 간격을 가진 일반 격자로 이미지를 오버레이.
- 각 격자 사각형에 있는 개체의 클래스와 격자 사각형 중심을 기준으로 한 객체의 Bounding box corner pixel coordinate 두가지 주요 정보가 표시된다.
- 사각형에 객체가 없는 경우 특수 dontcare 클래스 사용.
- object가 사각형 내에 있는지 여부 판단 coverage값 제공.
- 동일한 격자 사각형에 여러 object가 있는 경우 DetectNet은 격자 사각형 내에서 가장 많은 픽셀을 차지하는 개체를 선택.
- DetectNet Architecture
- Data layers ingest the training images and labels and a tranformer layer applies online data augmentation.
- A fully-convolutional network performs feature extraction and prediction of object classes and bounding boxes per grid square.
- Loss functions simultaneously measure the error in the two tasks of predicting the object coverage and object bounding box corner per grid square.
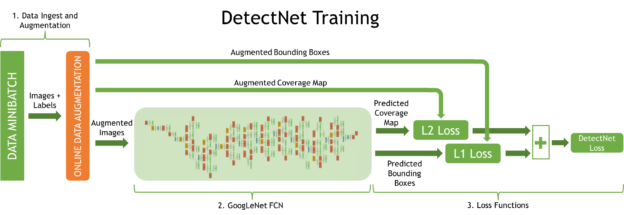
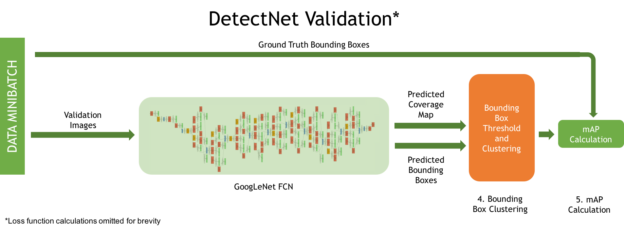
- A clustering function produces the final set of predicted bounding boxes during validation.
- A simplified version of the mean Average Precision(mAP) metric is computed to measure model performance against the validation dataset.
- DetectNet의 FCN 서브 네트워크는 데이터 입력 레이어, 최종 pooling 레이어가 없는 GoogleNet과 동일한 구조이다.
- 사전 훈련된 GoogLeNet모델을 사용하여 detectNet을 초기화할 수 있도록 함으로써 훈련 시간을 줄이고 최종 모델 정확도를 향상시키는 주요 이점이 있다.
- FCN은 컨볼루션 신경망, 완전히 연결된 레이어가 없다.
- 이는 네트워크가 다양한 크기의 입력 이미지를 수용할 수 있고, strided 슬라이딩 윈도우 방식으로 CNN을 효과적으로 적용할 수 있음을 의미한다.
- 출력은 DetectNet입력 레이블과 유사하게 이미지에 오버레이 될 수 있는 실수값의 다차원 배열이다.
- DetectNet은 두개의 손실함수의 선형조합을 사용.
- coverage_loss 훈련 데이터 샘플의 모든 그리드 사각형에서 실제 및 예측된 개체 범위 간의 차이 제곱의 합.
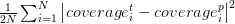
- bbox_loss : 그리드 정사각형에 포함된 객체에 대한 bbox의 실제 및 에측 corner에 대한 평균 L1손실.
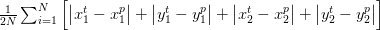
- 훈련 목표 => Caffe는 손실값의 가중치 합을 최소화한다.
'Robot, Autonomous Vehicle' 카테고리의 다른 글
[GPS]NMEA Parsing and Saving with C (0) 2022.11.07 [GPS]NMEA Output Message (0) 2022.11.07 [Python OpenCV ROS] cv.cap으로 딴 이미지 compressedImage msg로 publish하기 (0) 2021.03.02 [ROS USB_CAM] 한 머신에서 multi usb_cam node 켜기 (0) 2021.03.02 [Darknet ROS] darknet_ros yolov3 코드 이것 저것 수정 (2) 2021.03.02